ORNL Research
Adiabatic Quantum Support Vector Machines
This page summarizes the ORNL internship work and paper results comparing classical SVM training with an adiabatic quantum approach on D-Wave hardware.
Internship context: Oak Ridge National Laboratory (May 2023 - Aug 2023), with prior baseline work in Jun 2022 - Aug 2022.
Publication
Paper: Adiabatic Quantum Support Vector Machines
Publication metadata / DOI: 10.1007/s42484-025-00280-6
Note: the hosted PDF is the accepted manuscript (author version), not the Springer version of record.
Problem and method
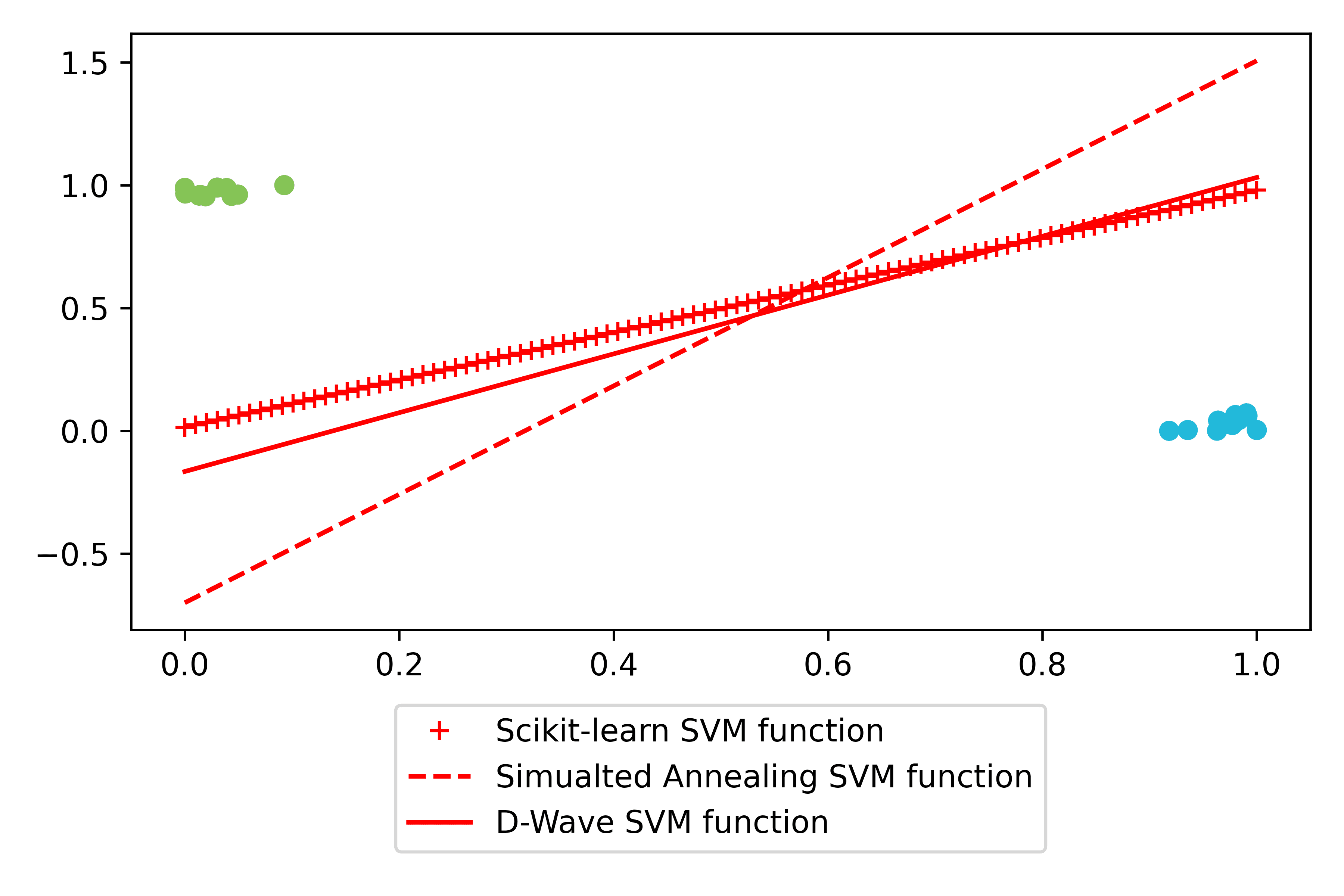
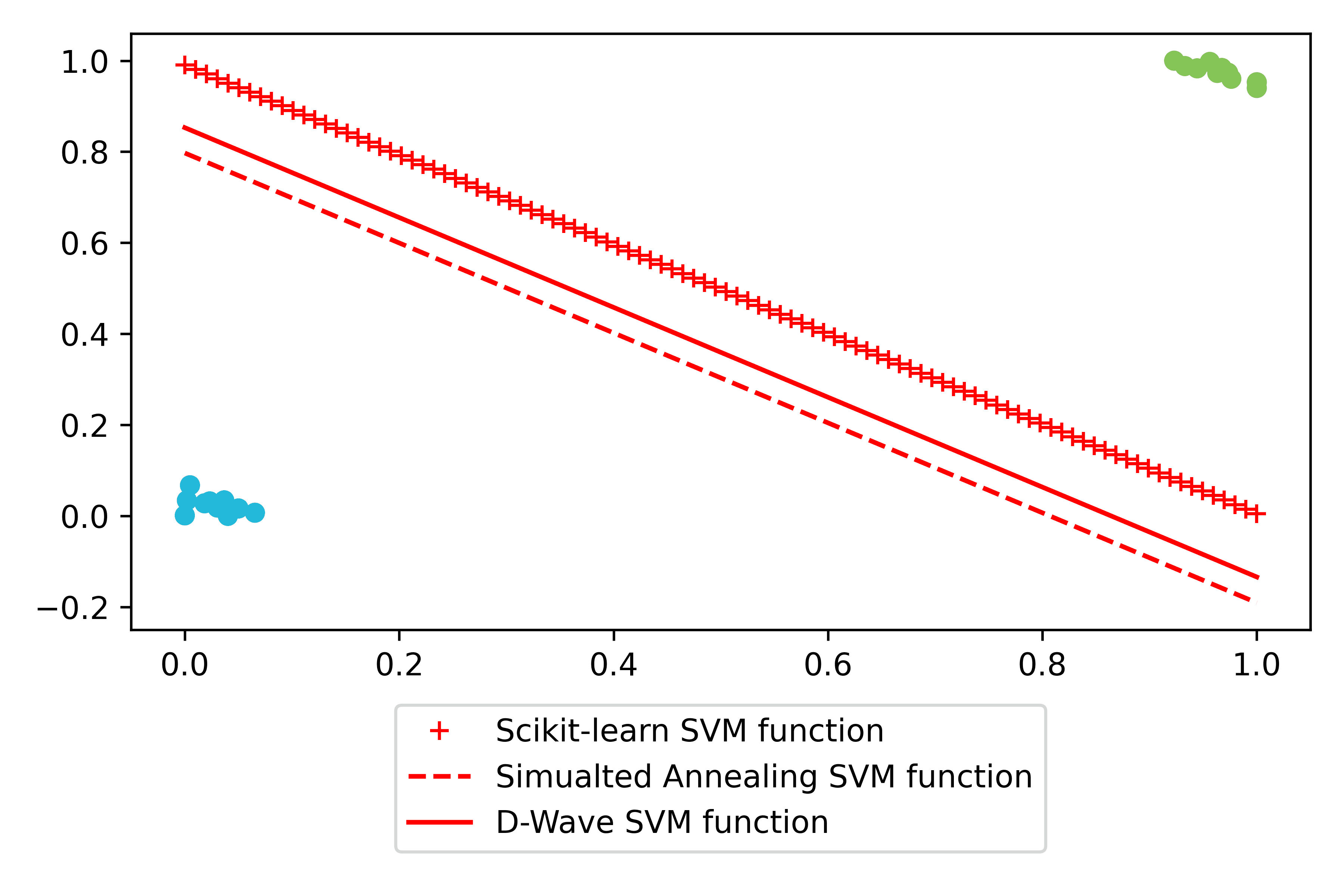
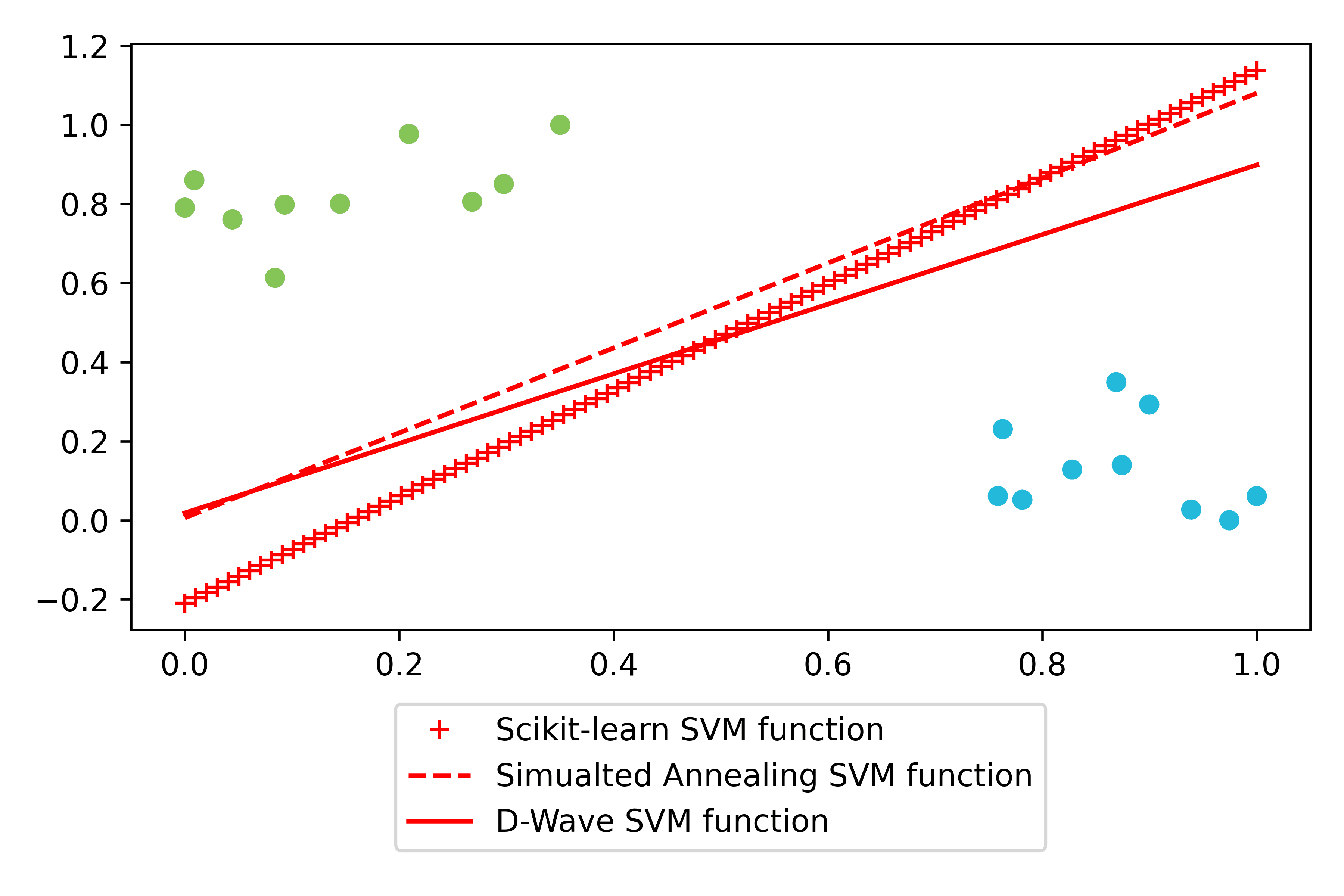
The project tested whether SVM training can be accelerated by mapping the optimization to a QUBO formulation and solving it with adiabatic quantum annealing.
Evaluation compared three approaches: classical Scikit-learn SVM, D-Wave quantum annealing, and simulated annealing. Metrics included classification accuracy and end-to-end compute time (QUBO conversion, embedding, hardware access, and solve steps).
Theoretical framing in the paper: classical training scales as O(N^3), while the quantum formulation is analyzed as O(N^2) when precision is fixed.
Key findings
Feature-scale speedup
3.5x to 4.5x
Quantum SVM training was faster than the classical baseline on very high-feature synthetic datasets.
Peak result in this study
3.69x faster
Observed at 8,388,608 features in the feature-scaling experiment.
Point-scaling result
4.48x faster
Observed at 52 training points in the point-scaling experiment.
Accuracy profile
Near-parity on many datasets
Quantum results were often close to classical results and matched on several synthetic and Iris pairings.
Accuracy snapshot
| Dataset | Classical | Quantum | Notes |
|---|---|---|---|
| Synthetic random | 100% test | 100% test | All approaches found strong separating hyperplanes. |
| Iris Setosa vs Virginica | 100% test | 100% test | No meaningful gap between approaches. |
| WBC | 95.0% test | 93.1% test | Quantum remained competitive. |
| Digits 0 vs 1 | 99.2% test | 97.5% test | Simulated annealer failed to find viable solutions. |
| Lambeq | 100% test | 88.7% test | Harder NLP task with larger accuracy gap. |
Figure walkthrough