PAPI
Design and Evaluation of a Standardized Interface for AMD GPU Performance Metrics
This work delivered a portable and low-overhead AMD GPU/APU monitoring interface for PAPI, designed to remain stable across device generations and ROCm software transitions.
Key Contributions
- Portable, low-overhead, probe-based interface design for AMD GPUs: introduces a portable interface that abstracts vendor-specific API differences, keeps per-call overhead low, and uses probe-based runtime discovery across GPU generations and software releases.
- Empirical validation of overhead, portability, and monitoring interval: establishes near-native per-call overhead relative to direct AMD SMI calls, confirms consistent access across evaluated GPU generations and ROCm releases, and identifies practical polling intervals.
- Platform-scoped reference of supported metrics and limits: documents the supported metrics on the evaluated platform to enable reproducible and comparable studies.
- Integration with PAPI: provides seamless incorporation into the PAPI framework, extending support to current AMD GPU/APUs while preserving continuity for existing users and tools.
Thesis
Objective: Modern high-performance computing systems increasingly rely on GPU accelerators, but differences and updates in vendor APIs make cross-platform measurement difficult and force users to maintain vendor-specific code. This thesis targets a robust and vendor-neutral AMD GPU/APU monitoring interface for performance analysis, energy optimization, and reliability studies.
Design: The implementation is built on AMD SMI and integrated into the PAPI component model. It abstracts vendor-specific API differences while maintaining low overhead, automatically detects which metrics are supported by a specific device and driver, and exposes only those metrics for power/energy, temperature, engine activity, and interconnect bandwidth/link state.
Validation: Experimental results confirm near-native measurement overhead and consistent behavior across AMD GPU models and ROCm versions, reducing maintenance burden and improving reproducibility for cross-platform performance analysis in heterogeneous HPC environments.
Key thesis results
Measured overhead and validation scale
1.009x and 32 metrics x 500 reads
Geometric mean call-time ratio (standardized interface / direct AMD SMI) using TOST with +/-2% bounds. Per-metric latency analysis covered fast, medium, and slower call categories.
Portability validation
MI210, MI250X, MI300A
Built, enumerated, and read supported metrics across ROCm 6.4.x, 7.0.x, 7.1.x, and 7.2.x.
Coverage expansion
342 vs 80 metrics
On MI300A with ROCm 7.0.1, AMD SMI exposed substantially more device-unique metrics than ROCm SMI.
Integration with PAPI
PAPI Integration
Seamless incorporation into the PAPI framework, extending functionality to current AMD GPU/APUs and ensuring continuity for existing users and tools.
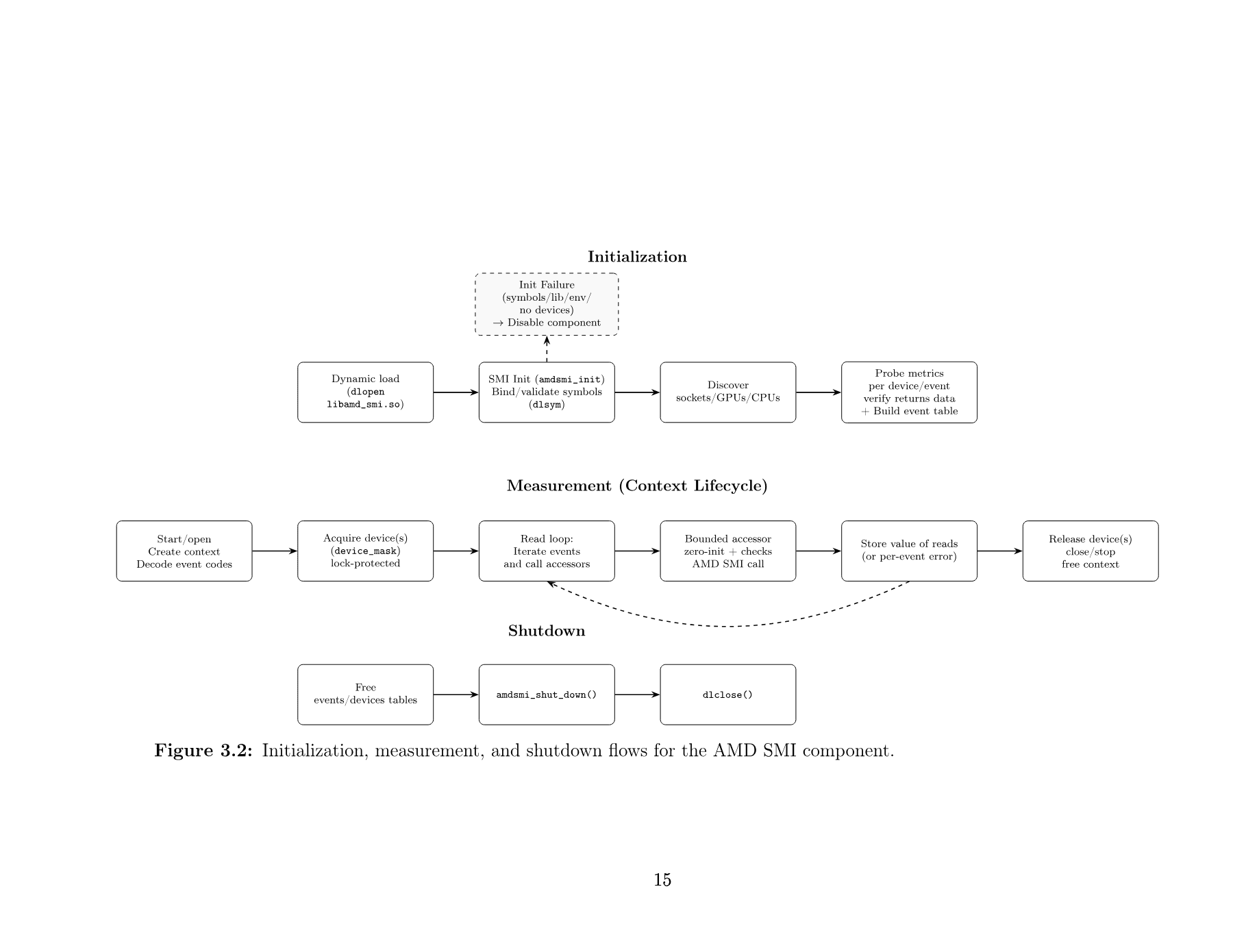
AMD SMI Architecture
The design implements a portable, low-overhead abstraction layer over AMD SMI so that AMD GPU/APU metrics can be enumerated and sampled consistently through PAPI across hardware and ROCm versions.
- Key design choices: probe-based runtime discovery validates metric availability before exposure, dynamic library loading with primary/fallback symbol binding handles API divergence, and bounded accessors keep the read path safe and low-latency.
- Runtime event registration: at initialization, the component builds an event table from device probes so unsupported counters are never exposed for enumeration or sampling.
- Concurrency and ownership: per-device ownership is enforced using a lock-protected device mask so concurrent eventsets in the same process do not sample the same GPU simultaneously.
- Architecture and lifecycle: initialization loads and validates AMD SMI symbols, discovers devices, and builds events; measurement opens context, acquires device ownership, and executes accessor reads; shutdown releases context resources and unloads library state.
- Module organization: core lifecycle state in
amds.c, event mapping inamds_evtapi.c, context and locking inamds_ctx.c, metric read accessors inamds_accessors.c, and PAPI vector integration inlinux-amd-smi.c.
Global Equivalence Experiement
This experiment compares per-call read latency between the standardized interface and direct AMD SMI calls on MI300A with ROCm 7.0.1. For each metric and source, the measurement loop runs on a pinned CPU core and records 500 iterations.
Equivalence is evaluated with Two One-Sided Tests (TOST) using +/-2% bounds on log call-time ratios. The geometric-mean ratio is 1.009 with a 98% confidence interval of [0.999, 1.019], indicating near-native overhead for the standardized path.
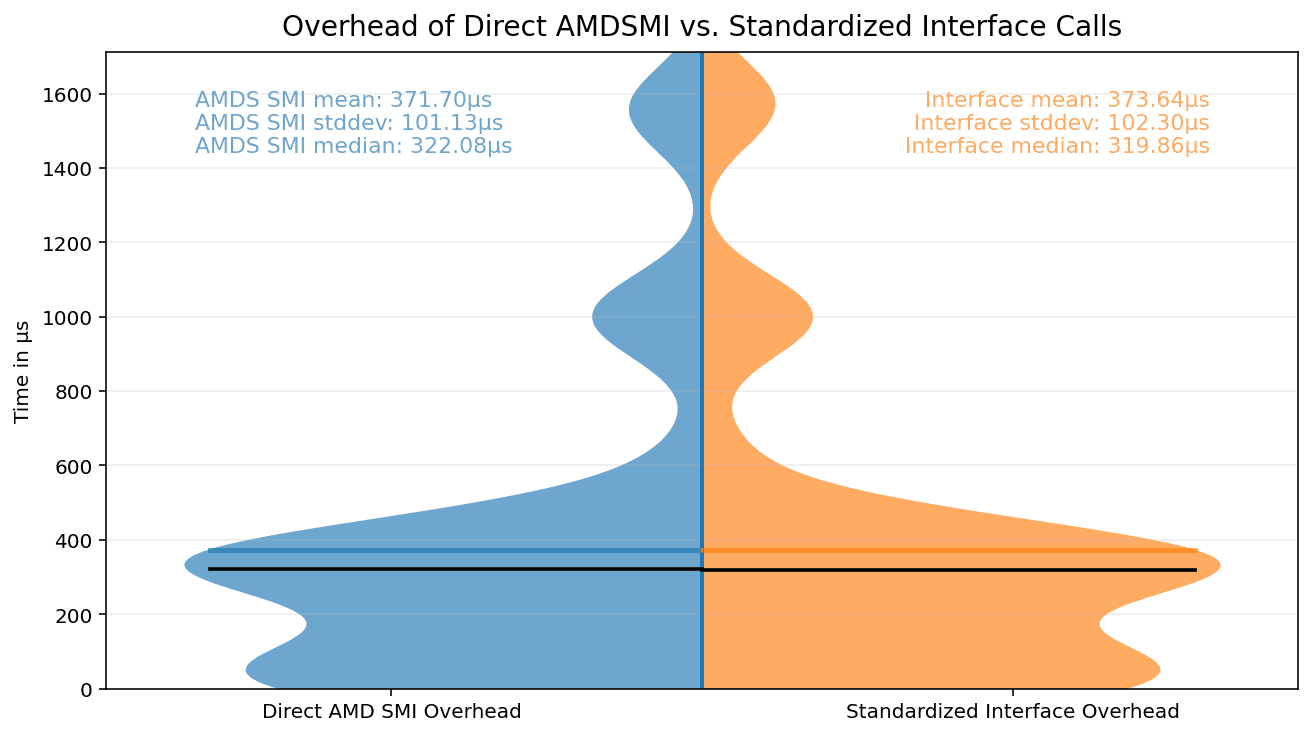
| Quantity | Estimate | 98% CI | Interpretation |
|---|---|---|---|
| Geometric-mean ratio (SI/AMD SMI) | 1.009 | [0.999, 1.019] | Within +/-2% bounds |
| Cross-metric mean (AMD SMI) | 371.70 us | --- | Absolute reference |
| Cross-metric mean (SI) | 373.64 us | --- | +0.52% vs SMI |
Portability coverage by device and ROCm version
The evaluation verifies that the interface design and implementation handle differences in available metrics across GPU generations and ROCm releases by compiling, enumerating, and reading metrics on 2 MI210, 8 MI250X, and 4 MI300A systems under ROCm 6.4.x, 7.0.x, 7.1.x, and 7.2.x.
Only metrics supported by the specific device and ROCm release are counted. Metrics not supported on a given device or ROCm version are not exposed for enumeration or sampling. Portability is achieved through probe-based runtime discovery of metrics, exposing only supported counters.
| Device | ROCm 6.4.x | ROCm 7.0.x | ROCm 7.1.x | ROCm 7.2.x | ||||
|---|---|---|---|---|---|---|---|---|
| 6.4.0 | 6.4.1 | 6.4.2 | 6.4.3 | 7.0.1 | 7.0.2 | 7.1.1 | 7.2.0 | |
| 4 MI300A | 259 | 259 | 259 | 259 | 342 | 341 | 342 | 342 |
| 8 MI250X | N/A | 375 | N/A | N/A | N/A | 356 | N/A | N/A |
| 2 MI210 | 345 | N/A | N/A | N/A | 333 | N/A | 333 | N/A |
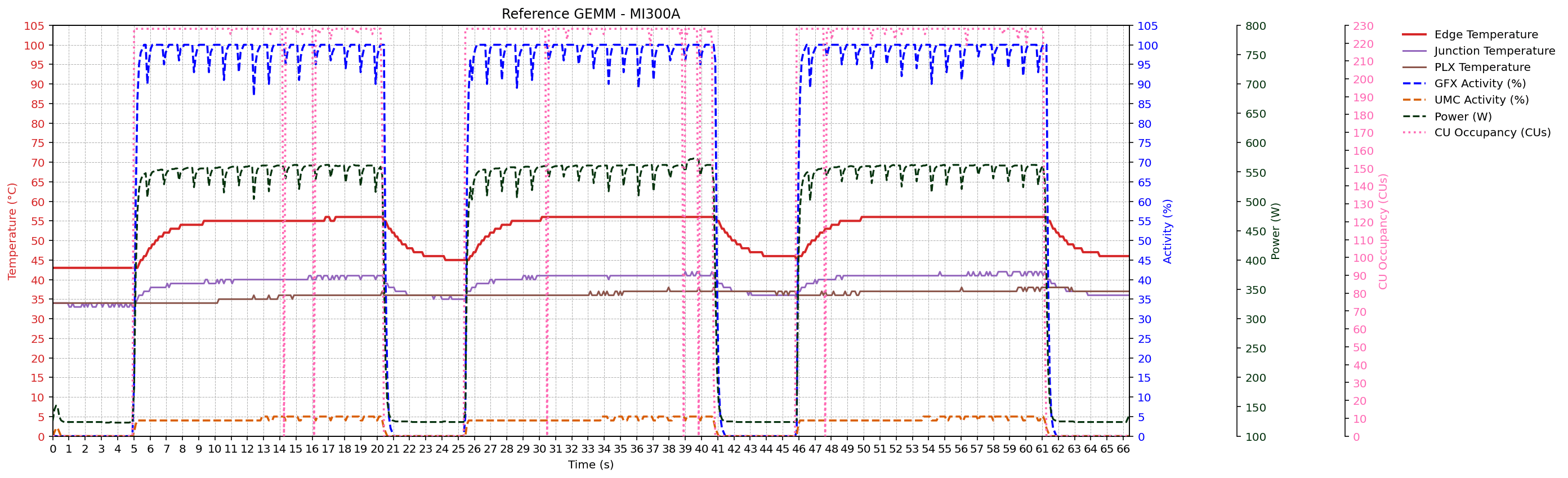
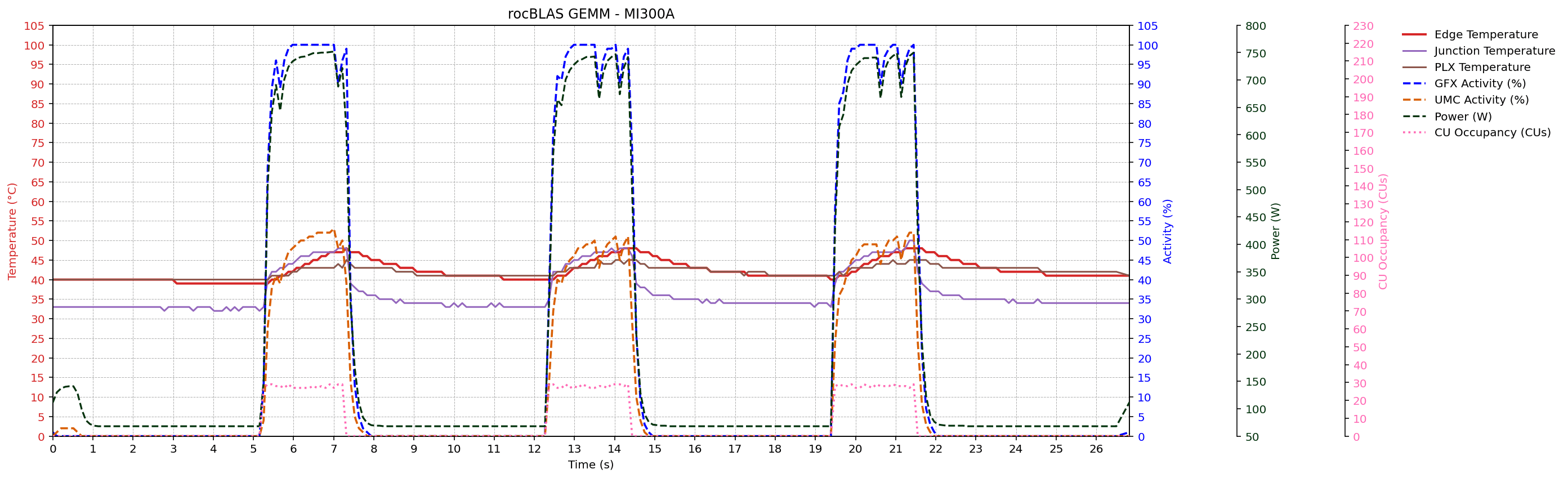
GEMM workload traces
After portability and metric enumeration checks, the thesis evaluates metric behavior under controlled GEMM workloads on MI300A, MI210, and MI250X systems. Sampled signals include GFX activity, UMC activity, power, edge/junction/PLX temperatures, and CU occupancy (where supported).
Across devices, traces preserve the expected temporal ordering of activity -> power -> temperature. The rocBLAS GEMM configuration (K = 131072) shows higher memory traffic and power than the reference GEMM configuration (K = 65536), consistent with the thesis analysis.
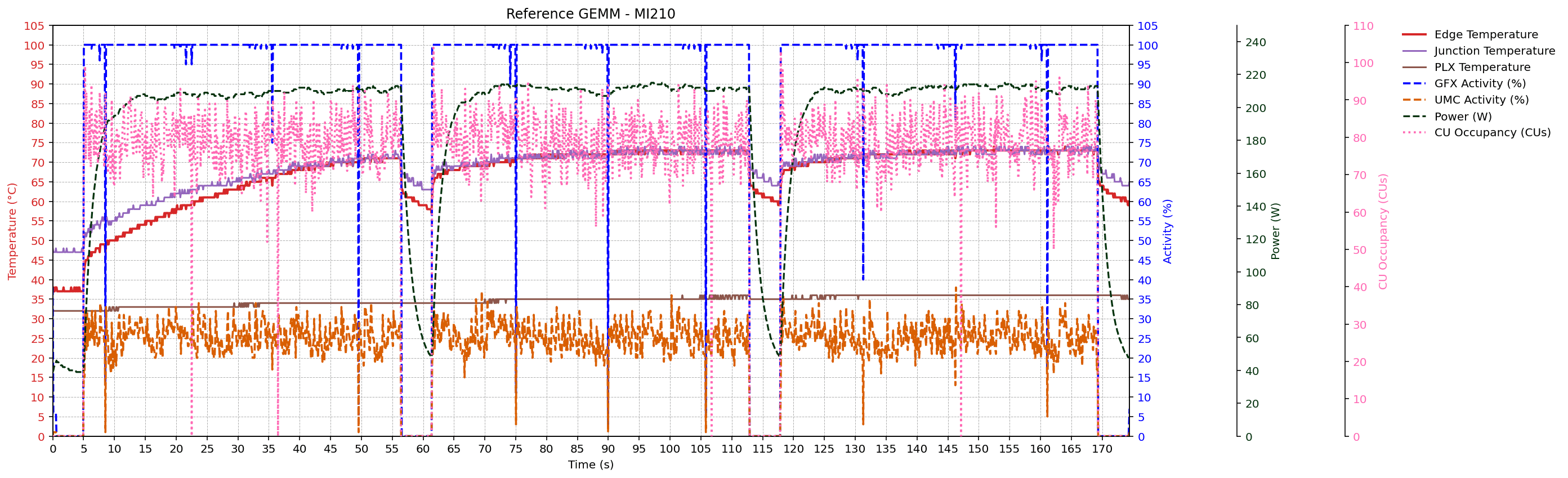
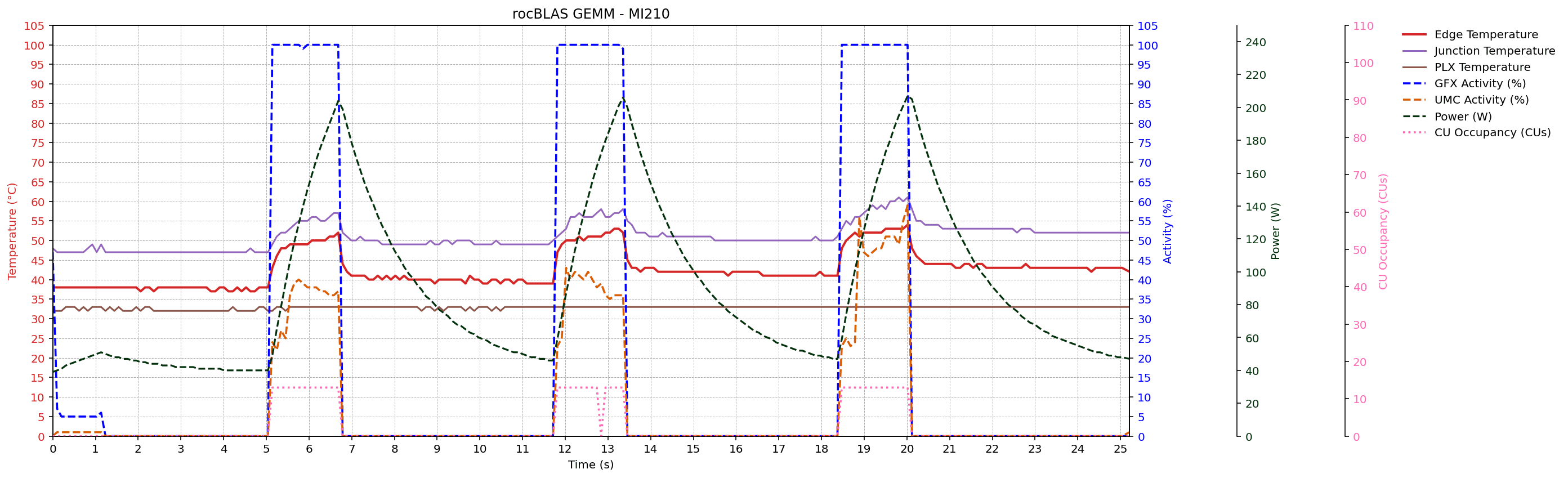
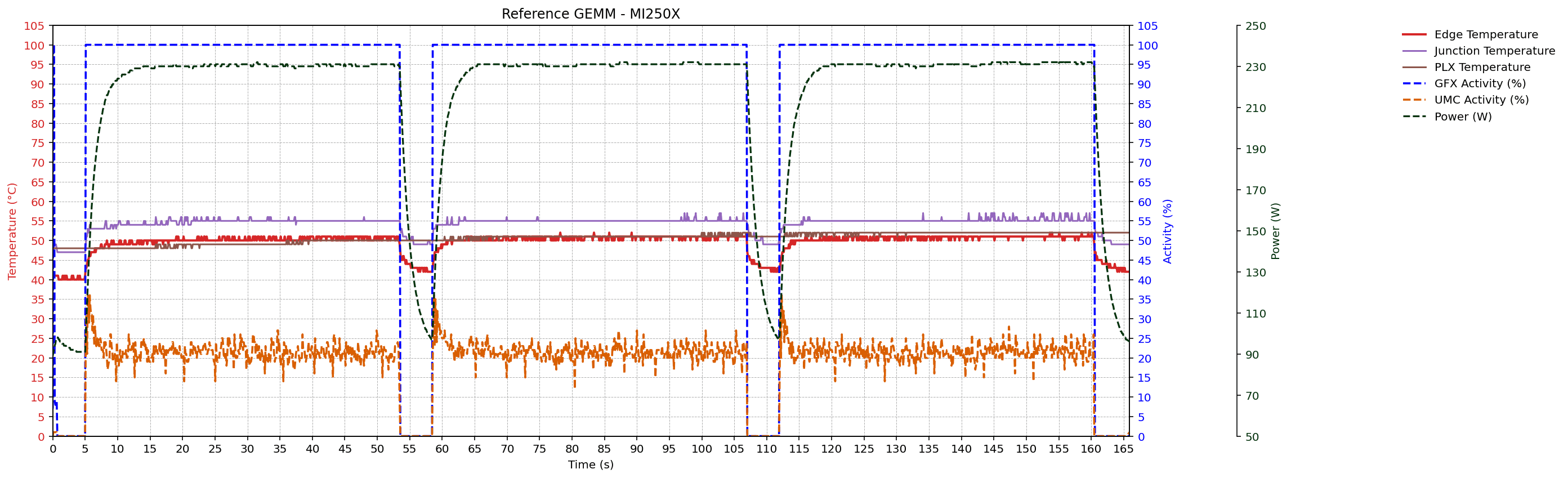
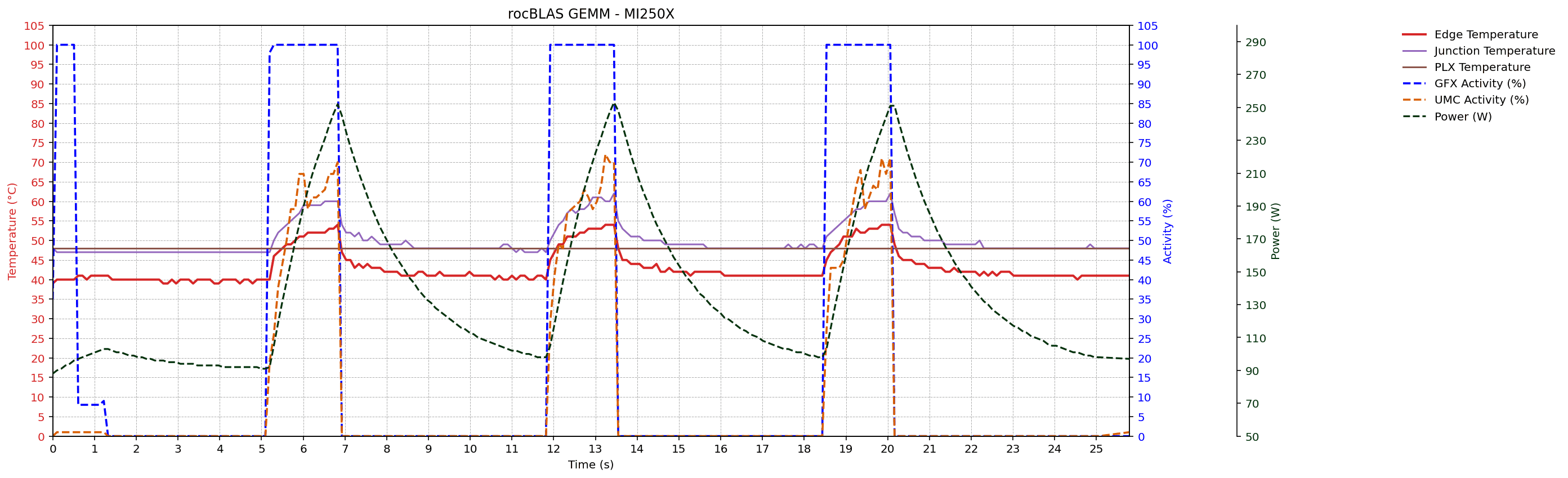
Monitoring Interval Experiement
This experiment examines how requested monitoring interval affects overhead and observable updates for power_current on MI300A (ROCm 7.0.1). Sampling intervals from 1 ms to 100 ms are tested during a 100 s run with repeated rest/load phases.
The table reports completed reads, per-call wall time, total time spent in reads, effective interval, and value changes. Results show the expected tradeoff: 1-2 ms intervals yield more distinct updates but higher sampling overhead, while longer intervals reduce overhead and capture fewer changes.
| Interval (ms) | Reads | Mean +/- s.d. (us) | Time in reads (s) | Eff. interval (ms) | Changes (count) |
|---|---|---|---|---|---|
| 1 | 100000 | 589.33 +/- 193.69 | 58.93 | 1.00 | 6753 |
| 2 | 50000 | 785.27 +/- 176.53 | 39.26 | 2.00 | 5854 |
| 5 | 20000 | 792.63 +/- 186.40 | 15.85 | 5.00 | 3644 |
| 10 | 10000 | 799.71 +/- 183.06 | 8.00 | 10.00 | 2360 |
| 20 | 5000 | 798.92 +/- 177.15 | 3.99 | 20.00 | 1474 |
| 50 | 2000 | 841.12 +/- 167.66 | 1.68 | 50.00 | 830 |
| 100 | 1000 | 854.48 +/- 168.04 | 0.85 | 100.00 | 457 |
References
Thesis PDF: Design and Evaluation of a Standardized Interface for AMD GPU Performance Metrics
Related publication: arXiv:2401.12485